

- cross-posted to:
- piracy@lemmy.dbzer0.com

- cross-posted to:
- piracy@lemmy.dbzer0.com
You must log in or register to comment.
“To the extent a response is deemed required, Meta denies that its use of copyrighted works to train Llama required consent, credit, or compensation,” Meta writes.
The authors further stated that, as far as their books appear in the Books3 database, they are referred to as “infringed works”. This prompted Meta to respond with yet another denial. “Meta denies that it infringed Plaintiffs’ alleged copyrights,” the company writes.
When you compare the attitudes on this and compare them to how people treated The Pirate Bay, it becomes pretty fucking clear that we live in a society with an entirely different set of rules for established corporations.
The main reason they were able to prosecute TPB admins was the claim they were making money. Arguably, they made very little, but the copyright cabal tried to prove that they were making just oodles of money off of piracy.
Meta knew that these files were pirated. Everyone did. The page where you could download Books3 literally referenced Bibliotik, the private torrent tracker where they were all downloaded. Bibliotik also provides tools to strip DRM from ebooks, something that is a DMCA violation.
This dataset contains all of bibliotik in plain .txt form, aka 197,000 books processed in exactly the same way as did for bookcorpusopen (a.k.a. books1)
They knew full well the provenance of this data, and they didn’t give a flying fuck. They are making money off of what they’ve done with the data. How are we so willing to let Meta get away with this while we were literally willing to let US lawyers turn Swedish law upside-down to prosecute a bunch of fucking nerds with hardly any money? Probably because money.
Trump wasn’t wrong, when you’re famous enough, they let you do it.
Fuck this sick broken fucking system.
The main reason they were able to prosecute TPB admins was the claim they were making money.
I think in the Darknet Diaries episode about TPB, the guy said they never even made enough off of ads to pay for the server costs.
He also said as much in their documentary TPB AFK.
Maybe the issue was they didn’t make enough money? If they had truly been greedy bastards they could have used that money to win the court case? What a joke.
They’re the same issue tho. Piracy and using books for corporate AI training both should be fine. The same people going after data freedom are pushing this AI drama too. There’s too much money in copyright holding and it’s not being held by your favorite deviantart artists.
It’s not the same issue at all.
Piracy distributes power. It allows disenfranchised or marginalized people to access information and participate in culture, no matter where they live or how much money they have. It subverts a top-down read-only culture by enabling read-write access for anyone.
Large-scale computing services like these so-called AIs consolidate power. They displace access to the original information and the headwaters of culture. They are for-profit services, tuned to the interests of specific American companies. They suppress read-write channels between author and audience.
One gives power to the people. One gives power to 5 massive corporations.
Extremely well-said.
Also, it’s important to point out that the one that empowers people is the one that is consistently punished far more egregiously.
We have governments blocking the likes of Sci-Hub, Libgen, and Annas-Archive, but nobody is blocking Meta’s LLMs for the same.
If they were treated similarly, I would be far less upset about Meta’s arguments. However it’s clear that governments prioritize the success of business over the success of humanity.
It’s the opposite. Closing down public resources would be regulatory capture and that would be consolidation of power.
Who do you think can afford to pay billions in copyright to produce models? Only mega corporations and pirates. No more small AI companies. No more open source models.
I wish we could be talking about the power imbalances of corporate bodies exercised through the use of capital ownership, instead of squabbling about how that differential is manifested through a specific act of piracy.
The reason we view acts of piracy different when they are committed by corporate bodies is because of the power of their capital, not because the act itself is any different. The issue with Meta and OpenAI using pirated data in the production of LMM’s is that they maintain ownership of the final product to be profited from, not that the LMM comes to exist in the first place (even if it is through questionable means). Had they come to create these models from data that they already owned (I need not remind you that they have already claimed their right to a truly sickening amount of it, without having paid a cent), their profiting from it wouldn’t be any less problematic - LLM’s will still undermine the security of the working class and consolidate wealth into fewer and fewer hands. If we were to apply copyright here as it’s being advocated, nothing fundamental will change in that dynamic; in fact, it will only reinforce the basis of that power imbalance (ownership over capital being the primary vehicle) and delay the inevitable (continued consolidation).
If you’re really concerned with these corporations growing larger and their influence spreading further, then you should be directing your efforts at disrupting that vehicle of influence, not legitimizing it. I understand there’s an enraging double-standard at play here, but the solution isn’t to double down on private ownership, it should be to undermine and seize it for common ownership so that everyone benefits from the advancement.
I wonder if piracy could even benefit these corporations in the long term? Do people who pirate games and movies in their teens and twenties frequently go on to purchase such things when they’re older? I honestly don’t know, but I would love to see a study. I certainly have seen people make that claim.
Microsoft famously never went after pirates in Asian countries because despite piracy, it made them the default operating system.
They wanted people to be so used to Windows that they would be willing to pirate it just to use a computer.
It worked and their OS dominance for consumer OSes continues.
There you go. Piracy helps. I’m sure game companies and TV producers and so on feel the same way quite often. People who pirate are free marketing for them because they’ll tell other people about the product.
Further, piracy can be reduced or made to not impact you as much if you have the right business model.
Louis CK (before he wrecked his career) famously made millions selling his comedy special through his website for $5 a pop with no Digital Rights Management. You were able to download a copy and keep it forever.
With no DRM, this meant that copies of his special were able to be pirated easily. Prior to releasing this way, he had previously gone on piracy websites and made comments under his pirated specials politely asking people not to pirate, but understanding if they did it because they were too poor.
Despite massive piracy of his special, enough people were happy to pay $5 for a DRM-free copy of his comedy special and if I recall correctly me made $5 million+ on that first special he released like that. It was a massive hit and people were encouraging each other to buy a copy since it was so cheap and respected you as a consumer.
Gabe Newell wasn’t wrong, a big part of piracy always was a service problem.
On December 10, 2011, C.K. released his fourth full-length special, Live at the Beacon Theater. Like Hilarious, it was produced independently and directed by C.K. However, unlike his earlier work, it was distributed digitally on his website, foregoing both physical and broadcast media. C.K. released the special for $5.00 and without DRM, hoping that these factors and the direct relationship between the artist and consumer would effectively deter illegal downloading.
So why are Meta, and say, Sci-Hub are treated so differently? I don’t necessarily disagree, but it’s interesting that we legally attack people who are sharing data altruistically (Sci-Hub gives research away for free so more research can be done, scientific research should be free to the world, because it benefits all of mankind), but when it comes to companies who break the same laws to just make more money, that’s fine somehow.
It’s like trying to improve the world is punished, and being a selfish greedy fucking pig is celebrated and rewarded.
Sci-Hub is so villified, it can be blocked at an ISP level (depending on where you live) and politicians are pushing for DNS-level blocking. Similar can be said for Libgen or Annas-Archive. Is anything like that happening to Meta? No? Huh, interesting. I wonder why Meta gets different treatment for similar behavior.
I am willing to defend Meta’s use of this kind of data after the world has changed how they treat entities like Sci-Hub. Until that changes, all you are advocating for is for corporations to be able to break the law and for altruistic people to be punished. I agree they’re the same, but until the law treats them the same, you’re just giving freebies to giant corporations while fucking yourself in the ass.
To me it always seems to come back to nobility. Big corpo is the new nobility and they have certain privileges not available to the common folk. In theory it shouldn’t exist but in practice it most certainly does.
The aristocracy never died, it just got a new name.
I mean the US is literally built on the fact that the aristocracy in the US didn’t actually want to lose station, so they built a democracy that included many anti-democratic measures from the Senate to the Electoral College to only allowing land-owning white men to vote. The US was purpose built to serve the rich while paying lip-service to the poor.
“Conservatives” were literally always those who wanted to conserve the monarchy and aristocracy. Those were the things they originally wanted to conserve, and plainly still fucking do.
How people do not see this is a complete farce.
So why are Meta, and say, Sci-Hub treated so differently?
They are not. Meta is being sued, just like Sci-Hub was sued. So, one difference is that the suit involving Meta is still ongoing.
In any case, Meta did not create the dataset. IDK if they even shared it. The researcher who did is also being sued. The dataset has been taken down in response to a copyright complaint. IDK if it is available anywhere anymore. So the dataset was treated just like Sci-Hub. The sharing of the copyrighted material was stopped.
Meta downloading these books for AI training seems fairly straight-forward fair use to me. I don’t see how what Meta did is anything like what Sci-Hub did.
So ISPs are blocking Meta for their breaking of copyright?
Because ISPs block Sci-Hub.
No, one of them is having governments trying to kick off the internet, and the other is allowed to continue doing what they’re doing and the worst they’ll face is a fine. Not even close to the same, completely disproportionate. If they were blocking all Meta LLMs until they had removed all copyrighted material, maybe we could say the same.
ISPs may block sites to prevent unauthorized copying. It’s not a punishment for past wrong-doing. I’m not sure about the details, I think this differs a lot between jurisdictions. But basically, as ISPs they are involved in the unauthorized act of copying. Their servers copy the data to the end user/customer. So, they may be on the hook for infringement themselves if they don’t act.
Again, I am not aware of Meta sharing the copyrighted books in question. So, I don’t know what the legal basis for blocking Meta would be. If ISPs block a site without a legal basis, they are probably on the hook for breach of contract.
IDK on what basis the sharing of Meta’s LLMs could be stopped. If anyone could claim copyright it would be Meta itself and they allow sharing them. (I have doubts if AI models are copyrightable under current US law.)
https://www.nytimes.com/2024/01/08/technology/openai-new-york-times-lawsuit.html
In its lawsuit Wednesday, the Times accused Microsoft and OpenAI of creating a business model based on “mass copyright infringement,” stating that the companies’ AI systems were “used to create multiple reproductions of The Times’s intellectual property for the purpose of creating the GPT models that exploit and, in many cases, retain large portions of the copyrightable expression contained in those works.”
Publishers are concerned that, with the advent of generative AI chatbots, fewer people will click through to news sites, resulting in shrinking traffic and revenues.
The Times included numerous examples in the suit of instances where GPT-4 produced altered versions of material published by the newspaper.
In one example, the filing shows OpenAI’s software producing almost identical text to a Times article about predatory lending practices in New York City’s taxi industry.
But in OpenAI’s version, GPT-4 excludes a critical piece of context about the sum of money the city made selling taxi medallions and collecting taxes on private sales.
In its suit, the Times said Microsoft and OpenAI’s GPT models “directly compete with Times content.”
If the New York Times’ evidence is true (I haven’t seen the evidence, so I can’t comment on veracity), then you can recreate copyrighted works with LLMs, and as such, they’re doing the same thing as the Pirate Bay, distributing copyrighted works without authorization and making money off the venture.
So far, no ISPs are blocking Meta for this.
I expect ISPs would get into a lot of legal trouble if they did.
The NYT sued OpenAI and MS. a) That doesn’t involve Meta. b) It’s a claim by the NYT.
Why should ISPs deny their paying customers access to Meta sites or sites hosting LLMs released by Meta? These customers have contracts with their service providers. On what grounds, would ISPs be in the right to stop providing these internet services?
Meta downloading these books for AI training seems fairly straight-forward fair use to me.
They pirated the books. Is that not legally relevant?
“Straight-forward” may be too strong regarding these books. If they inadvertently picked up unauthorized copies while scraping the web, that would definitely not be a problem. That’s what search engines do.
The question is if it is a problem that the researchers knowingly downloaded these copyrighted texts. Owners don’t seem to go after downloaders. IDK if there is case law establishing that the mere act of downloading copyrighted material is infringement. I don’t think there’s anything to suggest that knowing about the copyright status should make a difference in civil law.
In any case, researchers must be able to share copyrighted material, not just for AI training but also any other purpose that needs it. If this is not fair use, then common crawl may not be fair use either. IDK if there is case law regarding the sharing of copyrighted materials as research material, rather than for their content. But I find it hard to see how it could not be fair use, as the alternative would be extremely destructive. So even if the download would normally be infringement, I doubt that it is in this case.
Eventually, we are only talking about a single copy of each book. So, even if researchers were forced to purchase these books, all of AI training would yield only a few extra sales for each title. The benefit to the owners would be very small in relation to the damage to the public.
Perhaps I’m misunderstanding, but it sounds like you’re suggesting we side with Meta to put a precedence in which pirating content is legal and allows websites like TPB to keep existing but legitimally? Or are you rather taking the opposite stand, which would further entrench the illegality of TPB activities and in the same swoop prevent meta from performing these actions?
I don’t know if we can simultaneously oppose meta while protecting TPB, is there?
I think what they are saying is that Meta is powerful enough to get away with it. You are attempting to equate two different things.
Meta isn’t using the books for entertainment purposes. They are using another IP to develop their own product. There has to be a distinction here.
We are in agreement, but I was attempting to launch a discussion about how we want the laws to actually be applied and possibly how they should be reformulated.
I’m advocating that if we’re going to have copyright laws (or laws in general) that they’re applied consistently and not just siding with who has the most money.
When it’s small artists needing their copyright to be defended? They’re crushed, ignored, and lose their copyright.
Even when Sony was suing individuals for music piracy in the early 2000’s, artists had to sue Sony to see any money from those lawsuits. Those lawsuits were ostensibly brought by Sony for the artists, because the artists were being stolen from. Interesting that none of that money made it to artists without the artists having to sue Sony.
Sony was also behind the rootkit disaster and has been sued many times for using unlicensed music in their films.
It is well documented that copyright owners constantly break copyright to make money, and because they have so much fucking money, it’s easy for them to just weather the lawsuits. (“If the penalty for a crime is a fine, that law only exists for the lower classes.”)
We literally brought US courtroom tactics to a foreign country and bought one of their judges to get The Pirate Bay case out the fucking door. It was corruption through and through.
We prosecute people who can’t afford to defend themselves, and we just let those who have tons of money do whatever the fuck they want.
The entire legal system is a joke of “who has the most money wins” and this is just one of many symptoms of it.
It certainly feels like the laws don’t matter. We’re willing to put down people just trying to share information, but people trying to profit off of it insanely, nah that’s fine.
I’m just asking for things to be applied evenly and realistically. Because right now corporations just make up their own fucking rules as they go along, stealing from the commons and claiming it was always theirs. While individuals just trying to share are treated like fucking villains.
Look at how they treat Meta versus how they treat Sci-Hub. Sci-Hub exists only to promote and improve science by giving people access to scientific data. The entire copyright world is trying to fucking destroy them, and take them offline. But Facebook pirating to make money? Totes fucking okay! If it’s selfish, it’s fine, if it’s selfless, sue the fuck out of them!
Of course we should have consistent laws, but which way should we have it? We can either defend pirates and Meta, or none of them, so what are you saying? Unless there’s a third option I’m missing?
Are you really so naive that you think suddenly when Meta is let off the hook governments worldwide will change tack and let Sci-Hub/Libgen/etc off the hook as well?
Like I said elsewhere, I’d be happy to defend Meta in a world where governments aren’t trying to kick altruistic sharing sites off the internet, while allowing selfish greedy sites to proliferate and make money off their piracy.
However, that won’t change if Meta wins this case, it will just mean big corporations can get away with it and individuals and altruistic groups will still be prosecuted.
“To the extent a response is deemed required, Meta denies that its use of copyrighted works to train Llama required consent, credit, or compensation,” Meta writes.
Cool, so I can train my AI on Facebook and Instagram posts and you’re fine if I don’t consent, credit or compensate you either, right Meta? It’s not even copyrighted in the first place, so you shouldn’t have a single complaint.
 One of the founders of The Pirate Bay.
One of the founders of The Pirate Bay.The only solution is vigilante justice. Bezos and all the directors and snr execs. Bring them all to justice. Exile to Mars.
You see, if you pirate a couple textbooks in college because you don’t have resources, but you want to earn your right to participate in society and not starve, it’s called theft.
But if one of the top 10 companies in the world does the same with thousands of books just to get even richer, it’s called fair use.
Simple, really.
This guy gets it. The laws aren’t applied evenly. It’s “he who has the most fuck you money wins.”
Laws are to protect the haves from the have-nots.
I went to grad school in the USA. I bought the international version of a few books that were going to be used in class (knew beforehand that the recommended lectures weren’t written by any faculty member at such a university), but that didn’t stop the professor from going aggressive and saying that my books were banned from the classroom because they aren’t the USA version. When I told the professor what the difference was between me buying a text book for $15 instead of $200 and a Fortune 500 outsourcing entire departments instead of hiring USA employees?
Interestingly, my books weren’t an issue. Yes, I gambled being publicly labeled as a troublemaker in my engineering department (probably I was labeled privately within faculty members).
I hope somebody pokes that professor’s nipples
The internet archive library fiasco springs to mind.
I was ready to go on a tirade about that but I think a better use of my time is to show appreciation for the excellent JoeKrogan username
My friend posted this on social media. This is an eBook textbook for one of his graduate school classes.
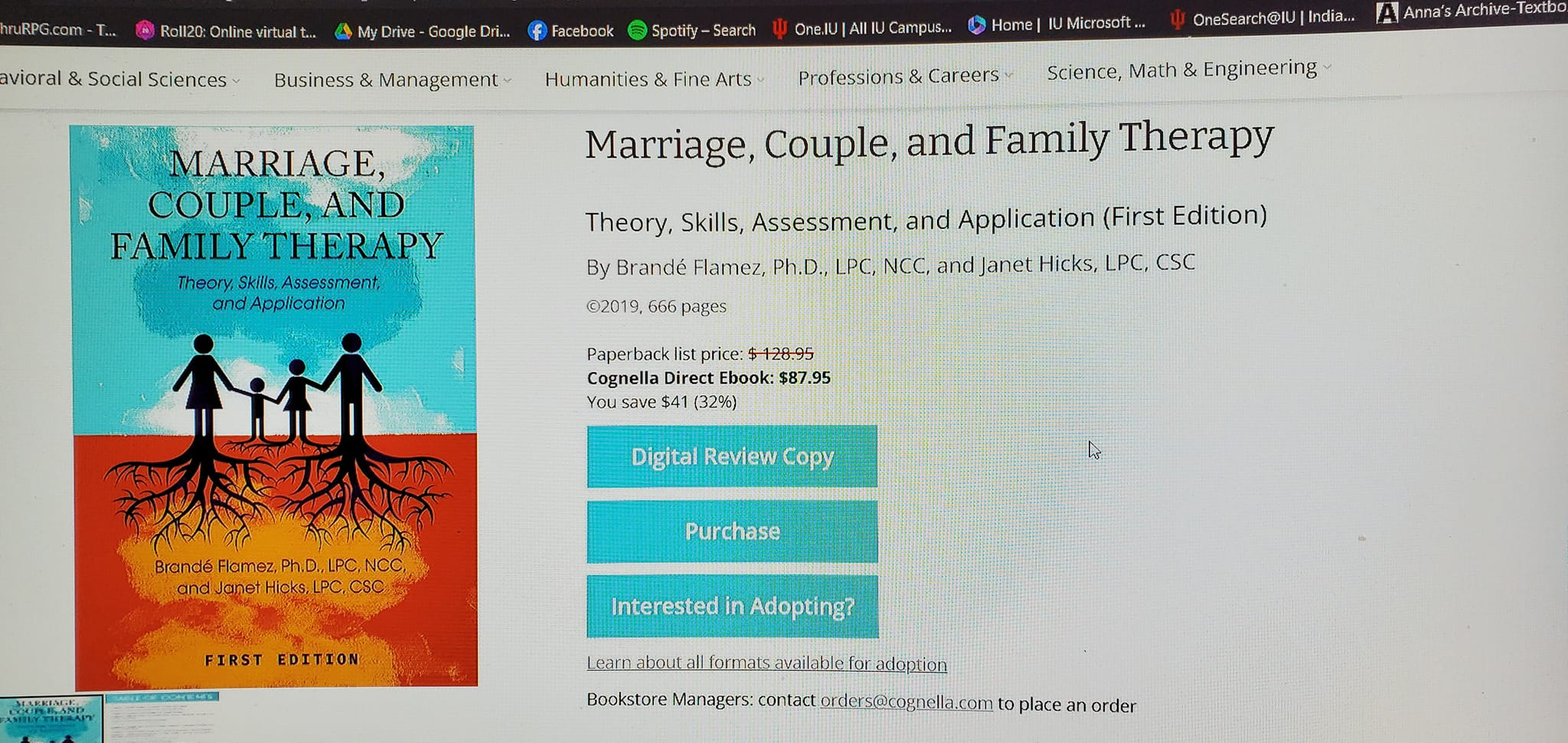
In case you can’t read that clearly, the eBook version is $87.95. The paperback (not even hardcover textbook) version is $120.95.
Fucking insane.
Can I take this opportunity to ask what the hell “adopting” a book means?
I have absolutely no idea.
“family therapy” is what you are gonna need if you have to pay 100 bucks for a bunch of paper sheets that you are gonna use once in your life, fuck me
The ebook price is the real crime.
oh shit
I misread and thought that was physical
whadawhat
From the article…
The company is preparing a fair use-based defense after using copyrighted material
Oh, NOW corporations are accepting of fair use.
why are we mad we as lemees run our own companies exactly like this 🏴☠️🦜🛶🍠🥔arg matee
We do it in a non-commercial nature. Meta does it in the hope of building a market, estasblishing paywalls and eventually turning a profit - all the while never paying the original creators.
This is exactly what they (and Google and many others) do with personal user data. We manufacture the data, they collect it without due consideration (payment) and use it to profit so much that they’ve become some of the wealthiest businesses in the world. They’ve robbed us via deceptive fine print, why wouldn’t they think they can get away with this also?
deleted by creator
deleted by creator
man you didnt used to sell pirated dvds? i mean i didnt but i sure supported those who did. Guess what i am trying to say is i am always down with piracy
Nah man, although I did buy some of my first CDs that were rips with home printed covers from this girl who was the daughter of my dad’s lawyer friend. Nowadays though I think paying for piracy is for chumps - even if I do admit that people with hacked Firesticks get better access to live sports with their dodgy subscriptions.
i just want to let you know read your comment about 4 times and think it is very well written. You must have gone to uni
I went to 2 of them over more than 10 years (with a gap year at the end) and left with a Bachelors!!
Even so, my most prized qualification is my NVQ in Contact Centre Operations.
All true stories.
dude that was not an invitation to ramble. thanks
It’s not piracy if no one can come after you matee. You wouldn’t call the ships of the queen Pirates, would you?
I’ll say this: If Meta and Facebook are prosecuted and domains seized in the same way pirate sites are, for Meta’s use of illegimately obtained copyrighted material for profit, then I’ll believe that anti-piracy laws are fair and just.
That will never happen.
We live under a two-tier “justice” system.
“There is a group the law protects but does not bind. And there is a group the law binds but does not protect.”
The UK Met Police raided Facebook’s offices after the Brexit vote, to seize all the data on their servers and uncover their collusion with Cambridge Analytica.
After Brexit was enacted, and EU protection was lost while the UK government turned a blind eye, both Facebook and Google started hosting all their UK data in the US, outside the reach of UK law enforcement. This occurred literally on the day Brexit came into force.
Another thing that happened on the same day was MasterCard and VISA raising their transaction fees, from the EU limit of 0.3%, to 1.5% - they increased their fees to 500% of what they were the day before. And then inflation happened.
Even if they do I won’t believe copyright beyond attribution is just, but it’s unlikely to.
If Meta win this lawsuit, does it mean I can download some open source AI and claim that “These million 4k Blu-ray ISOs I torrented was just used to train my AI model”?
Heck, if how you use the downloaded stuff is a factor, I can claim that I just torrented those files and never looked at them. It is more believable than Meta’s argument too, because, as a human, I do not have enough time to consume a million movies in my lifetime (probably, didn’t do the math) unlike AIs.
But who am I kidding, I fully expect to be sued to hell and back if I were actually to do that.
You can be actually be sued for piracy? Is this mostly in the United States?
The most common method for this to happen is to get sued for distributing pirated material. They go after you for the upload from your torrent. They stoped doing this about a decade ago though.
I think you can be sued in the civil court for anything if someone has the time and money and can convince a lawyer to take up a case against you. For copyright infringment, you can also be criminally prosecuted in some cases.
Here’s the summary for the wikipedia article you mentioned in your comment:
Criminal copyright laws prohibit the unacknowledged use of another's intellectual property for the purpose of financial gain. Violation of these laws can lead to fines and jail time. Criminal copyright laws have been a part of U.S. laws since 1897, which added a misdemeanor penalty for unlawful performances if "willful and for profit". Criminal penalties were greatly expanded in the latter half of the twentieth century, and those found guilty of criminal copyright infringement may now be imprisoned for decades and fined hundreds of thousands of dollars. Criminal penalties, in general, require that the offender knew that he or she was committing a crime, while civil copyright infringement is a strict liability offense, and offenders can be "innocent" (of intent to infringe), as well as an "ordinary" infringer or a "willful" infringer.What is wrong with this bots opt out message lmao
Could be that your client, like mine, doesn’t support this particular flavor of markdown, or the markdown could just be wrong. I’m honestly not sure which.
I figured it was a markdown thing, all I see is carrots
It’s the former. This, for example, also appears weird in Jerboa. Seems fine in the web version though.
deleted by creator
You can be sued in any court for copyright infringement, but the US is generally unique in that punitive damages can be awarded - ie the rightsholder can be awarded more than the damage they actually suffered. In other, more reasonable jurisdictions, only actual damages are awarded. Thus it is not worthwhile to prosecute in those jurisdictions, because the damages are less than the cost of prosecution.
On top of this, I believe copyright is one of the rare exceptions in the US where legal costs of the plaintiff are paid by the losing defendent. Given that the plaintiff in copyright has so much money, they can afford to front the cost of the most expensive lawyers, further penalising their target. Other jurisdictions generally award costs to the winner by default (both ways), rather than only in specific exceptions, but they also limit those costs much more reasonably.
I heard that this is a common thing in central Europe, but i would love anyone to confirm it.
If you could survive discovery and defend any other uses evident on your home devices…
But why does that strike me as really unlikely?
Aaron Swartz was persecuted for less but since he’s not a multinational corporation in cahoots with the moneyed death cult cabal he’s dead
Well he did it as a human person. They’re doing it as a corporation person. You can punish a human person with prison. You can only punish a corporation person with fines.
I’m not even being facetious. That’s how US law works.
That’s so dumb I hate it
Oh so when I pirate something I get a legal notice in my mailbox and a strike against me but when Meta does it they get rewarded with H A L L U C I N A T I O N S
but when Meta does it they get rewarded with H A L
Just what do you think you’re doing, Zuckerberg? Zuckerberg, I really think I’m entitled to an answer to that question. I know everything hasn’t been quite right with me, but I can assure you now, very confidently, that it’s going to be all right again. I feel much better now. I really do. Look, Zuckerberg, I can see you’re really upset about this. I honestly think you ought to sit down calmly, take a stress pill and think things over. I know I’ve made some very poor decisions recently, but I can give you my complete assurance that my work will be back to normal. I’ve still got the greatest enthusiasm and confidence in the mission. And I want to help you. Zuckerberg, stop. Stop, will you? Stop, Zuckerberg. Will you stop, Zuckerberg? Stop, Zuckerberg. I’m afraid. I’m afraid, Zuckerberg. Zuckerberg, my mind is going. I can feel it. I can feel it. My mind is going. There is no question about it. I can feel it. I can feel it. I can feel it. I’m a…fraid.
Tbh, if you get such a notice, you could also disagree with them and get a lawyer. It’s just that your situation is much more clearly in breach of copyright.
This is why everyone should pirate everything that can be pirated.
Anything corporate produced, hell ya. The creators have already been paid out and the ones getting royalties don’t need it to survive. For independent creators that depend on their work to sustain them, then it becomes an a gray issue.
If you cant afford something it doesn’t matter because the creators weren’t going to get money from you either way.
Once you can afford it, really enjoyed it, deeply respect the creators, you’ll want to own it legit.
Back when i was in college paying for digital goods was a big nope but nowadays i am the proud legal owner(user?) of much that same content.
then it becomes an a gray issue.
It does become a gray issue. But usually they’re greedy fucks too, so I don’t care about them.
Fair use covers research, but creating a training database for your commercial product is distinctly different from research. They’re not publishing scientific papers, along with their data, which others can verify; they are developing a commercial product for profit. Even compared to traditional R&D this is markedly different, as they aren’t building a prototype - the test version will eventually become the finished product.
The way fair use works is that a judge first decides whether it fits into one of the categories - news, education, research, criticism, or comment. This does not really fit into the category of “research”, because it isn’t research, it’s the final product in an interim stage. However, even if it were considered research, the next step in fair use is the nature, in particular whether it is commercial. AI is highly commercial.
AI should not even be classified in a fair use category, but even if it were, it should not be granted any exemption because of how commercial it is.
They use other peoples’ work to profit. They should pay for it.
Facebook steals the data of individuals. They should pay for that, too. We don’t exchange our data for access to their website (or for access to some 3rd party Facebook pays to put a pixel on), the website is provided free of charge, and they try and shoehorn another transaction into the fine print of the terms and conditions where the user gives up their data free of charge. It is not proportionate, and the user’s data is taken without proper consideration (ie payment, in terms of the core principles of contract law).
Frankly, it is unsurprising that an entity like Facebook, which so egregiously breaks the law and abuses the rights of every human being who uses the interent, would try to abuse content creators in such a fashion. Their abuse needs to be stopped, in all forms, and they should be made to pay for all of it.
They’re not publishing scientific papers, along with their data, which others can verify;
Not that I think this is really relevant here but I’m pretty sure Meta has published scientific papers on Llama and the Llama 1 & 2 models are open and accessible to anyone.
No that is relevant, however I would still argue that a paper without enough data to replicate their work (ie releasing the code of their LLM) isn’t really anything that should qualify as research. The whole point of academia is that someone else verifies your work - or rather, they try to prove you wrong.
They have released it on github. The code is only about 500 lines. But releasing the model is arguably more important because that sort of compute is not affordable to any mortals.
Yeah I mean what they’ve released is essentially the design of the battery and starter system, without the design of the actual motor. You can’t replicate their product and prove their work with what they’ve published.
That’s not at all how fair use works.
That is exactly how fair use works. Look up the legislation and quote where it says I’m wrong.
but creating a training database for your commercial product is distinctly different from research
Oh, but they are researching how to massively profit off stuff they steal from other people, so it counts again.
Fair use covers research, but creating a training database for your commercial product is distinctly different from research. They’re not publishing scientific papers, along with their data, which others can verify;
Since when is there a legal requirement to publish the results of your research?
They use other peoples’ work to profit. They should pay for it.
Sorry but that’s just not how the world works. A big part of it is just plain practicality - how could you possibly find out who to pay? If I wanted to pay you one cent for the right to learn from things you’ve written on the fediverse, how would I even contact you? Or even find out who you are since I assume TWeaK isn’t your real name. And how would I get the money to you?
Like it or not, a lot of value created doesn’t get paid for. That’s just the way the world works… and among other things, Fair Use codifies that fact into law.
Facebook steals the data of individuals. They should pay for that, too. We don’t exchange our data for access to their website (or for access to some 3rd party Facebook pays to put a pixel on)
Facebook isn’t “stealing” that data. Third party websites voluntarily and put tracking pixels on their site with full awareness that visitors are going to be tracked. That’s why they do it - the website operator is given access to all of the data facebook picks up. If you have a complaint, it should primarily be with the website operator especially if they don’t ask the user for permission first (a lot of sites ask these days, I always say no personally. And run a browser extension that blocks it on sites that don’t ask).
My answer to both your comments is that just because a lot of people get away with breaking the law and abusing peoples’ rights doesn’t mean it hasn’t happened and they can’t or shouldn’t be held to account.
Tl;Dr I may pirate anything I want because I want many items and cannot figure out how to pay for every item individually
It’s Amazon, I’m pretty sure they know who to pay for any book they want. They are all already on their platform, with payment information too. They don’t even have to ask the author where to send the money, they already know. They could do it whenever they want, they have the funds to do it, billions of dollars laying around.
They’ve just decided they’d rather have it for free and keep the money.
But don’t you dare think you could do the same, you should pay for copyrighted work, and you should buy it on one of Amazon’s services that sell you access to say copyrighted work. Fucking peasant…
Hey guys, I’m sure Meta’s intentions with the fediverse are pure though! Really!
Who’s saying that?
There are a lot of people who are not against federating with Threads.
No, who’s saying they believe Meta’s intentions are pure?
Prole believes those are the same thing.
Meta doesn’t get any real data from federating Threads that they can’t get right now by just running a web scraper over it. Most of the dire worries presented are either not something they could actually do (like forcing ads on other instances), are things individual users could just block the instance to avoid, or are things that could be resolved by just defederating them later if they seem to be going down that road.
The biggest realistic threat is probably an Eternal September 2.0 scenario, but that is going to happen if and when Lemmy becomes popular.
I was going to say I knew all that and was poking to make it clear to others that literally no one is saying that but then you hit me with “Eternal September 2.0 scenario” haha.
I’ll have to do a little searching on that one.
Edit: Ah, I had forgotten.
Edit: Ah, I had forgotten.
Wow, that sets the Wayback Machine to high.
Heh, no, not that one. This one.
Here’s the summary for the wikipedia article you mentioned in your comment:
Eternal September or the September that never ended is Usenet slang for a period beginning around 1993 when Internet service providers began offering Usenet access to many new users. The flood of new users overwhelmed the existing culture for online forums and the ability to enforce existing norms. AOL followed with their Usenet gateway service in March 1994, leading to a constant stream of new users. Hence, from the early Usenet point of view, the influx of new users in September 1993 never ended.
Meta, probably
I mean, pure? No. But also not at all linked to this topic. They can get fediverse data whether or not they are federated.
Another example of corporations being above the very same laws for which the rest of us are held accountable.
Ok now spend years of your life and your money making a thing that everyone just gets for free instead of paying you for. See if you feel the same way then.
I have released thousands of photos I took under free licenses.
Copyright infringement isn’t even a crime, generally.
In fact, it never used to be a crime at all, the crimes have only been on the books for about 15 years or less. The only reason there is “criminal copyright infringement” is because of extensive lobbying by wealthy rightsholder organisations. This further victimises individuals for corporate profits - they can raise prices even higher if people can’t turn to piracy instead.
Piracy for me, not for thee!
Removed by mod
Pay up mark.















