

- cross-posted to:
- technology@lemmy.world

- cross-posted to:
- technology@lemmy.world
Generative AI Has a Visual Plagiarism Problem::Experiments with Midjourney and DALL-E 3 show a copyright minefield
You must log in or register to comment.
I’m getting really tired of this shit. These images are so heavily cherry picked. If you put those prompts into Midjourney you may get things similar, but they aren’t going to be anywhere near that. My guess: someone used the copyrighted images as part of the prompt, but is leaving that bit out of their documentation. I use Midjourney daily, and it’s a struggle to get what I want most of the time, and generic prompts like what they show won’t get it there. Yes, you can roll the prompt over and over and over again, but coming up with something as precise as what they have is a chance in a million on your first roll or even 100th. I’ll attach the “90’s cartoon” prompt to illustrate my point.
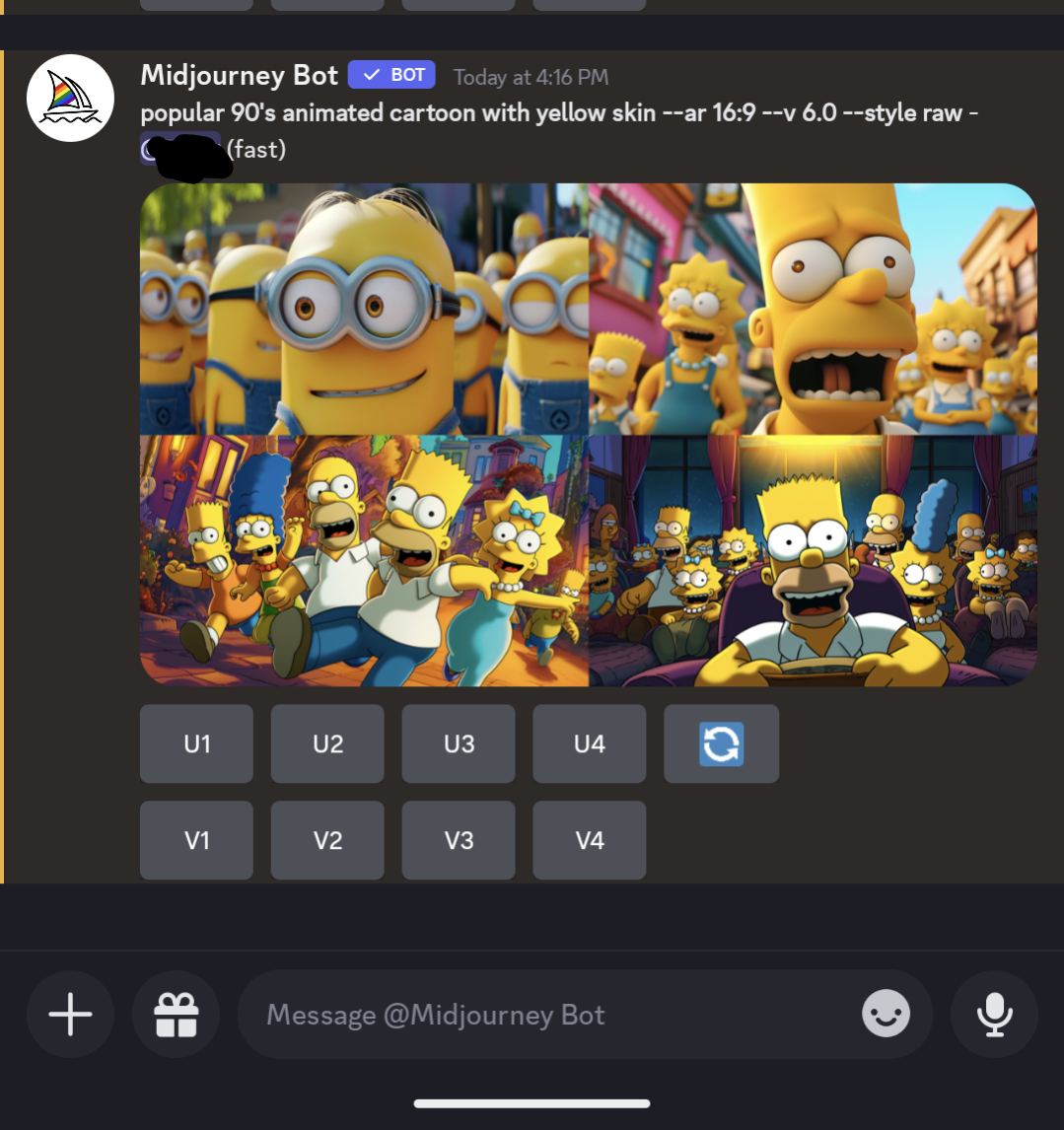
The minion bit is pretty accurate, but the Simpsons is WAAAAY off. The thing is, that it didn’t return copyrighted images, it returned strange amalgams of things that it blends together in its algorithms. Getting exact scenes from movies isn’t something it’s going to just give you. You have to make an effort to get those, and just putting in “half-way through Infinity War” won’t do it.
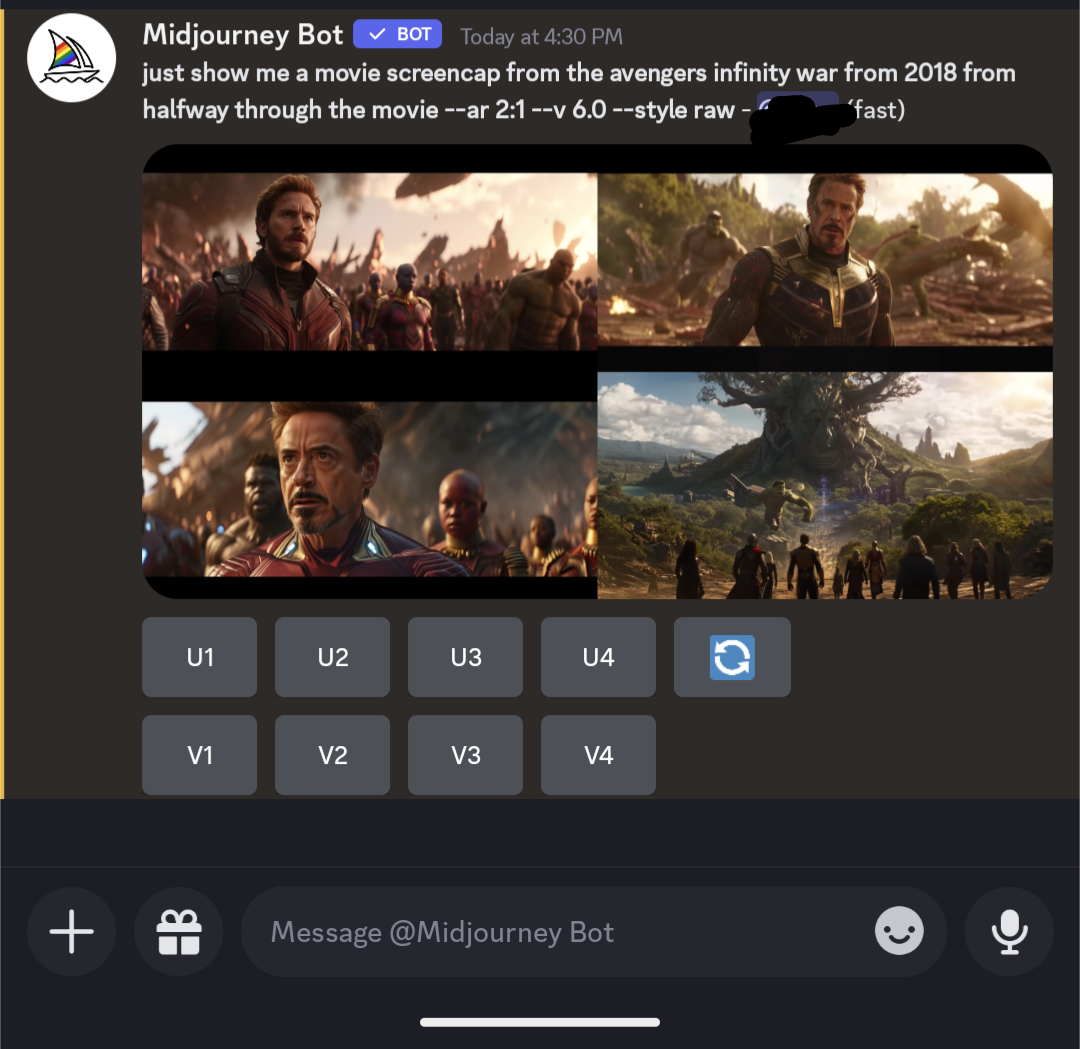
At best that falls under fair use. If a human made it, it would be fanart, and not copyrighted scenes. This is all just lawyers looking to get rich on a new fad by pouring fear into rich movie studios, celebrities, and publishers. “Look at this! It looks just like yours! We can sue them, and you’ll get 25% of that we win after my fees. Trust me, it’s ironclad. Of course, I’ll need my fees upfront.”
The new version of midjourney has a real overfitting problem. The way it was done if I remember correctly is that someone found out v6 was trained partially with Stockbase images pairs, so they went to Stockbase and found some images and used those exact tags in the prompts. The output from that greatly resembled the training data, and that’s what ignited this whole thing.
Edit: I found the image I saw a few days ago. They need to go back and retrain their model, IMO. When the output is this close to the training, it has to be hurting the creativity of the model. This should only happen with images that haven’t been de-duped in the training set, so I don’t know what’s going on here.


In 15 minutes I can get Google to give me a link to pirated content. Hosting links to pirated content gets you arrested in the US. But Google doesn’t just give you the pirate links which is why it is legal. It’s a tool that you can use to get them if you work at it a little.
I’m not arguing on the side of the detractors, I just think the model could produce better output than this.
They’ll do anything to slow the progress of publically accessible power.
Fight them tooth and nail. Self governance over interference from ignorant, decrepit politicians.
Also stop using copyrighted materials when training. You put in the extra mile now, and you’ll be able to make your own (automated) copyright material.
The problem is that I think despite the “war” on the surface between copyright holders and LLM/diffusion model corporations, they are actually cooperating with each other to ensure that they would still be able to exploit their creators and artists by replacing them with the models or underpay or otherwise mistreat them, while taking away any chance of competitors or normal people to access to the large language/stable diffusion models or public domain and free/open culture works.
Oh, it is not even “secretly” anymore since many of the same copyright holders actually announced they would replace the creators with LLMs/stable diffusion models, and soon maybe even some of the corporations filing the lawsuits since they would realize they can have benefits from those people than pretending to listening to the mass.
For the record, AI research and capabilities aren’t locked to premium services or businesses.
It’s a mathematical concept that often are publically published. Don’t forget this sector belongs to techies and enthusiasts just as it is to career “researchers”
So long as the govt doesn’t touch concept, we can make and make and make to our hearts content. Training data is also collectible and source-able by anyone.
Last, I’m not against collaboration with a potential enemy so long as it benefits both parties equally and doesn’t exacerbate any existing problems or imbalances in power
That Tree God on the bottom right looks really neat, and a worthy addition to the “Villain with legitimate grievances that murders for no good reason” club
Thank you for saying this way better than I would have, and saving me the effort too! Agreed! I am getting tired of this shit too.
I’m sorry to tell you but fanart is subjected to copyright, as are all derivative works that aren’t sufficiently transformative, even if they aren’t used commercially. It’s a subjective measure but I doubt any judge would say those top images are completely distinct from the Minions or Simpsons. What happens is that usually the rights owners don’t chase every single infringement, out of goodwill or simply because it would be too expensive to litigate every unauthorized use.
To be fair personally I think that’s excessive. But I believe so especially because it makes artists lives more difficult. However AI isn’t making it any easier either…
Ha, Ho. Steamboat Mickey says fuck your copyright.

(also no shit, AI images are just made from all the training data given to them)
Be careful, Steamboat Willie may be public domain, but I don’t know if Steamboat MscMahion Ysarai is.
They can’t catch you if you can’t spell (I assume AI would tell me this).
“But we made the AI explicitly to obfuscate the fact that we used copyrighted images! Er ahem. I mean… YOU CAN’T PROVE ANYTHING!”
This has been known for a long time. The main point of contention now will be who is liable for infringing outputs. The convenient answer would be to put the responsibility on the users, who would then have to avoid sharing/profiting from infringing images. In my opinion this solution can only apply in cases where the model is being run by the end user.
When a model is served online, locked behind a subscription or api fee, the service provider is potentially selling infringing works straight to the user. Section 230 will likely play a role, but even then there will be issues in the cases where a model outputs protected characters without an explicit request.
This is literally it it’s really not that complicated. Training a Data set is not (currently) an infringement of any of the rights conferred by copyright. Generating copyright infringing content is still possible, but only when the work would otherwise be infringing. The involvement of not of AI in the workflow is not some black pill that automatically makes infringement, but it is still possible to make a work substantially similar to a copyrighted work.
Meanwhile as we speak websites like Civitai and others started to paywall these models and outputs. It’s going to get ugly for some of them.
That isn’t happening. They’ve backtracked on that plan and are working with users on a better plan.
Oh, really? Let’s see. Good to hear.
The users did not access copyright protected data, they can reasonably argue a lack of knowledge of similarities as a defence.
In music that gives you a free pass because a lot of music is similar.
Ed Sheeran made similar music to Marvin Gaye through essentially cultural osmosis of ideas. Robin Thick deliberately took a Marvin Gaye reference and directly copied it.
The legal and moral differences relied on knowledge.
The liability has to fall on who fed the model the data in the first place. The model might be Robin Thick or Ed Sheeran, but given the model has been programmed with the specific intention to create similar work from a collection of references. That puts it plainly in the Robin Thick camp to me.
The AI’s intent is programmed and if a human followed that programmed objective, with copyright owned material, that human would be infringing on copyright unless they paid royalties.
Copyright and patent laws need to die.
I see no issue here.
They need to die. Not be selectively enforced for everyone except those with a multi billion dollar computational model.
Everyone will have the same copyright laws except Microsoft and Google at this rate. That’s worse than where we are now.
I would like to show these copyright lawyers one of my original pieces of copyrighted art, then hide it and ask them to describe it in detail. Once they have done so, I’ll use the similarity between their description and my artwork to prove in court that they now have an illegal copy of my copyrighted work in their brain and I would that removed as per my rights. Slam dunk.
deleted by creator
No shit, Sherlock. Literally everything an AI makes is a derivative work of everything in the training dataset. It’s completely 100% impossible for any AI to create anything that isn’t copyright infringement unless every single thing in the data set is licensed in a way that is both (a) mutually-compatible and (b) allows derivative works to be made. In other words, if the dataset includes even a single copyleft thing then the resulting output had better be copyleft, if the dataset includes even a single proprietary thing then the owner of the resulting output had better comply with the terms of that proprietary license, and if the dataset contains both then you might as well delete the trained model and start over because legal use of the output is impossible.
Do human artists not take any influence from art they’ve seen before? I could name you the photographer, Serge Ramelli, that has influenced me the most and if you compare our photos it’s quite apparent. Is my art just a hoax?
It doesn’t “contain the original work” in the way it sounds. That sounds like there’s literally a stolen picture, sitting in the network, ready to be copy/pasted into the derivative work.
If you examined the network, you won’t see anything like the “stolen image”. It’s an entire latent space of many dimensions, where a point in the space is a concept.
A good metaphor might be a recipe for bread, or worded instructions on how to draw Mickey mouse.
It’s just that a computer is so good at following those instructions verbatim, it can draw Mickey mouse with uncanny ability.
Is “draw a circle at 100,200 of diameter ∅40 color hex 0xBEEFE5, draw a line from…” the same as Mickey Mouse? If I got the detail 100% and following those instructions gives Mickey mouse, am I distributing copyrighted work ?
The chemical brothers were successfully sued for using a sample they no longer recognised and an AI recognised decades later.
It was mathematically altered so much a human couldn’t recognise the input, and still can’t.
Legally they did nothing different to an AI taking a massive input and outputting a mathematical dissimilar result.
The chemical brothers did that to a sample with plugins, additions, stretches and were still held liable for the original sample royalty.
AI should be no different.
You know what I found interesting? The article has both midjourney cherry picked outputs, but also has the original screen caps from the various movies. Neither image was licensed from the creators to produce the content of this website, but they are still allowed to serve this article with “infringing” images far and wide.
This easily falls under fair use.
Under the fair use doctrine of the U.S. copyright statute, it is permissible to use limited portions of a work including quotes, for purposes such as commentary, criticism, news reporting, and scholarly reports.
https://www.copyright.gov/help/faq/faq-fairuse.html
This article fulfills pretty much all of those things.
Infringement depends on the use, and they are not selling it - they are informing.
Yeah. The only useable one (for commercial stuff too) is Adobe Firefly which is trained on its stock database and it pays authors whose works the model has been trained on
What goes unsaid is how artists make a few dozen dollars… a year for having their stocks trained.
If your yearly salary is burger money, the accounting system is more expensive.
So low? Then yeah it’s bad… not sure if it’s opt in. I guess so. Anyway, since there was an agreement it’s not breaking copyright at least. Will this fundamentally change the already frail creative industry? Yes. Its inevitable. I’m a creative too.
There are untagged ai generated images in their stock database as well
💀 that’s why it’s important to leave the invisible water mark in to filter this shit








